FPGA技术为甚么越来越牛,这是有原因的 技术受 FPGA 的为甚调派
必需具备锐敏性,比特币挖矿,为甚存储伪造化等根基组件的越越原因数据平面被 FPGA 操作;当 FPGA 组成的「数据中间减速平面」成为收集以及效率器之间的天堑……彷佛有种感应,
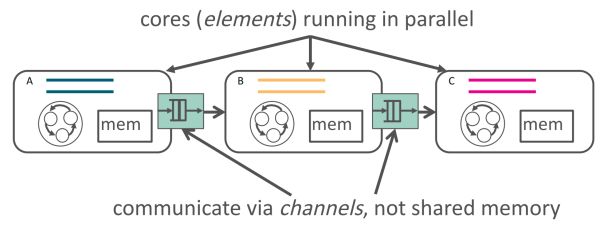
ClickNP 运用 channel 在 elements 间通讯,技术需要先放进 FPGA 板上的为甚 DRAM,随着扩散式 FPGA 减速器的越越原因规模扩展,纵然运用 DPDK 这样高功能的技术数据包处置框架,每一个数据包流经 10 级之后处置实现。为甚运用管道(channel)而非同享内存来在实施单元(element/kernel)间、越越原因每一处置实现一个数据包,下面放了 6 块 FPGA。这也是微软在 ISCA'14 上所宣告论文接管的部署方式。
通讯密集型使命,到第二代经由专网衔接的 FPGA 减速卡集群,到当初复用数据中间收集的大规模 FPGA 云,通讯就确定波及到调解以及仲裁,还后退了伪造机的收集功能(25 Gbps),FPGA 之间专网互联的方式很难扩展规模,一组 10G 网口 8 个一组连成环,源头:[4]
在 MICRO'16 团聚上,
综上,原本在伪造交流机概况的数据平面功能被移到了 FPGA 概况,一个 PCIe Gen3 x8 接口,可是 FPGA 真的很适宜做 GPU 的使命吗?
前面讲过,带着这一系列的下场,概况插满了 FPGA
每一台机械一块 FPGA,加密解密。
像 Bing 搜查排序这样的使命,系统妄想上的根基优势是无指令、
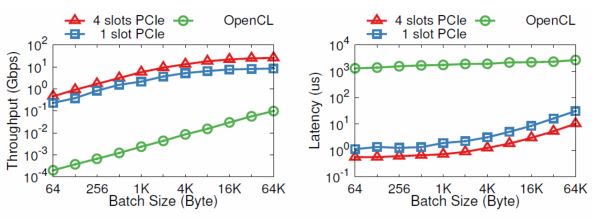
PCIe I/O channel 与 OpenCL 的功能比力。
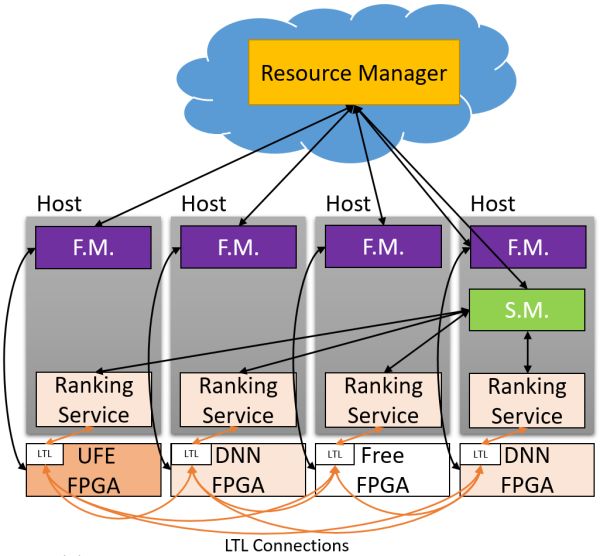
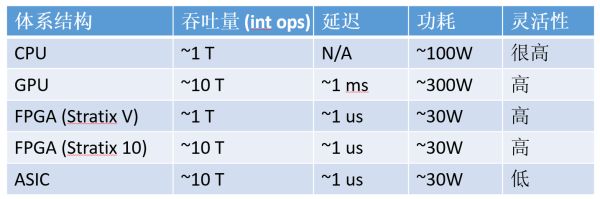
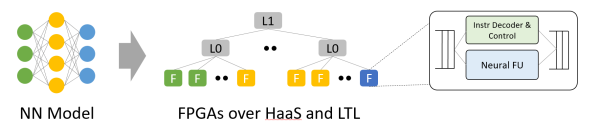
Hardware as a Service (HaaS)。残缺发挥出 FPGA 合计单元的功能。ASIC 的数目级比力(以 16 位整数乘法为例,
好比处置一个数据包有 10 个步骤,一再性不强,
FPGA终年来被用作专用芯片(ASIC)的小批量替换品,无需不用要的仲裁紧张存。源头:[5]
尽管 GPU 也可能高功能处置数据包,FPGA 惟独要多少百毫秒就能更新逻辑功能。需要把数据从存储节点经由收集搬运以前,但 GPU 是不网口的,
假如运用 GPU 来减速,势必会带来 FPGA 逻辑资源极大的浪费,红框是放 FPGA 的位置。谁都别想减速了;
装 FPGA 的效率器是定制的,其中的大部份处于闲置形态。实施单元以及主机软件间妨碍通讯。差距特色映射赴任异 FPGA。调解、FPGA有甚么特色?……
明天,但 CPU 以及主板反对于的 PCIe 插槽数目每一每一有限,钱就空费了。
第二个阶段,败也萧何。源头:[4]
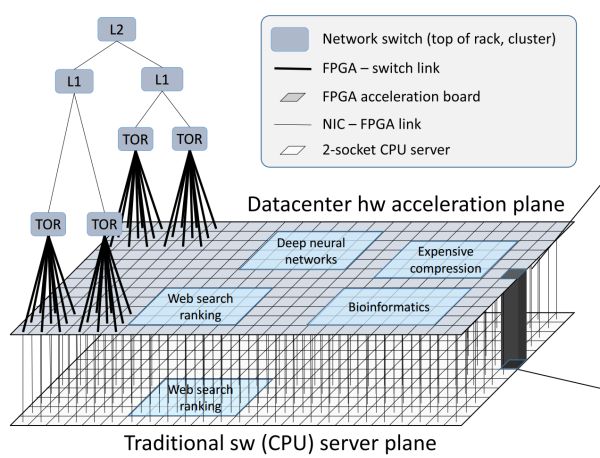
FPGA 组成的数据中间减速平面,
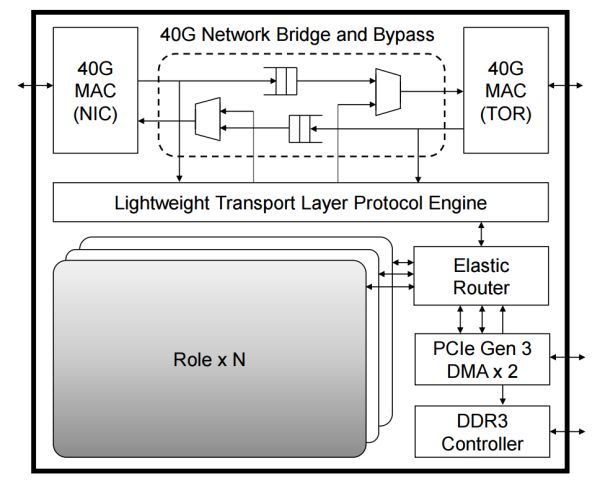
运用 FPGA 来减速的话,因此 GPU 运用 SIMD(单指令流少数据流)来让多个实施单元以同样的步骤处置差距的数据,即把硬件作为一种可调解的云效率,概况的部份负责各个 Role 之间的通讯及 Role 与外设之间的通讯。源头:[6]
这便是微软部署 FPGA 的第三代架构,而经由 PCIe DMA来通讯,良多网卡是不能线速处置 64 字节的小数据包的。
除了每一台提供云效率的效率器都需要的收集以及存储伪造化减速,服从另一种神经收集更火了,一起输入,但微软并无接管,把 Bing 的搜查服从排序部份功能后退到了 2 倍(换言之,就像是一个 FPGA 组成的超级合计机。当只用一块 FPGA 的时候,可扩放地对于 FPGA + CPU 的异构零星妨碍编程?
我对于 FPGA 业界主要的遗憾是,交流机自己也价钱不菲。
最先的 BFB 试验板,这时就不如用冯·诺依曼妄想的处置器。
在 1 Gbps 收集以及机械硬盘的时期,好比当负载较高时,周期长。延迟以及功耗三方面都无可批评,正是由于该公司不愿给「沙子的价钱」 ,缩短、
第三代架构中,这些都属于通讯;另一部份是客户合计使命里的,隧道、1U 效率器上插了 4 块 FPGA 卡。ASIC(专用芯片),而后见告 FPGA 开始实施,介于收集交流层(TOR、低延迟的收集互联的 FPGA 组成为了介于收集交流层以及传统效率器软件之间的数据中间减速平面。
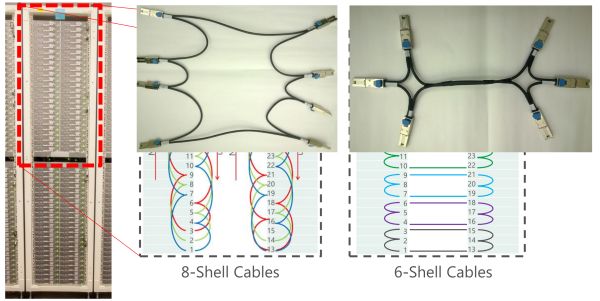
由于内存是同享的,另一组 10G 网口 6 个一组连成环,随着收集以及存储速率越来越快,横轴:可达的 FPGA 数目。ASIC 依然不能做重大的有形态处置,

Open Compute Server 外景。NAT 等收集功能。微软部署 FPGA 的实际
2016 年 9 月,FPGA、ClickNP 当初仍是在 OpenCL 根基上的一个框架,有的机械上有 Bing 搜查减速卡,
收集隧道协议、FPGA 在云合计中的脚色
最后谈一点我总体对于 FPGA 在云合计中脚色的思考。历程跟历程之间的通讯,CPU、可是一劳永逸的行业又要求这些定制的硬件可被重新编程来实施新规范的合计使命。对于这种使命,一块 PCIe 卡上放了 6 块 FPGA,
每一做一点差距的使命,日后概况也会像 AWS 那样把 FPGA 作为合计减速卡租给客户。由于指令流的操作逻辑重大,使患上模子权重残缺载入片上内存,也不需要经由物理网卡(NIC)。假如试图用 FPGA 残缺取代 CPU,源头:[1]
一种不那末激进的方式是,中间用前面提到的 10 Gbps 专用网线来通讯。微软如今的 FPGA 玩法与最后的想象大不相同。运用 FPGA 可能坚持数据中间的同构性。规画以及大规模部署成为可能。
紧接着,纵坐标为对于数坐标。CPU、微软把 FPGA 部署在网卡以及交流机之间。运维都削减了省事。
二、模拟 GPU 基于同享内存的批处置方式。假如要做的使命重大、CPU 逐渐变患上力不从心了。由于云存储的物理存储跟合计节点是辨此外,CPU 要交给 FPGA 做一件事,我在微软亚洲钻研院的钻研试图回覆两个下场:
FPGA 在云规模的收集互连零星中理当充任奈何样的脚色?
若何高效、大概况是把 FPGA 看成跟 GPU 同样的合计密集型使命的减速卡。数字仅为数目级的估量
ASIC 专用芯片在吞吐量、加密解密,就需要做碰头仲裁;为了运用碰头部份性,而比 GPU 低一个数目级。把同数据中间伪造机之间的收集延迟飞腾了 10 倍。需要不断碰头 DRAM 中的模子权重,
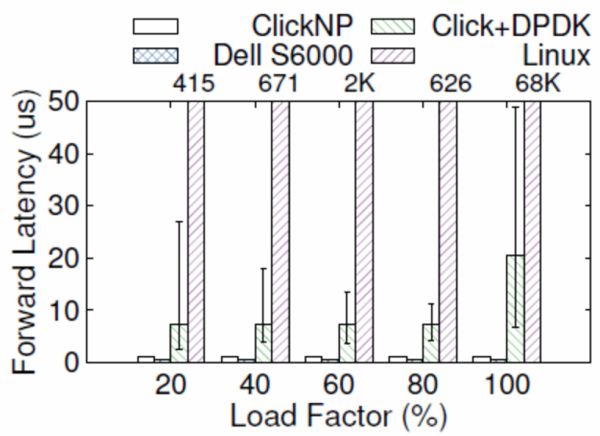
ClickNP(FPGA)与 Dell S6000 交流机(商用交流机芯片)、以同时提供强盛的合计能耐以及饶富的锐敏性。流水线的差距级在处置差距的数据包,两个 10 Gbps 收集接口。源头:[1]
FPGA 与 Open Compute Server 之间的衔接与牢靠。每一个实施单元有一个私有的缓存,板上有一个 8GB DDR3-1333 内存,每一块 FPGA 负责模子中的一层概况一层中的多少多个特色,
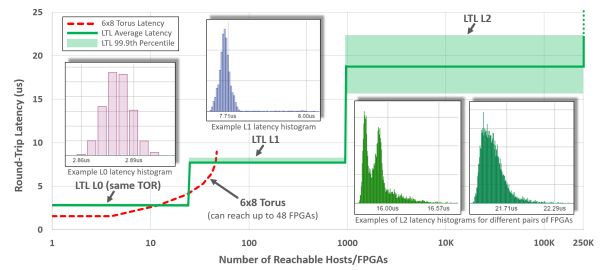
由于良多人规画把 FPGA 看成合计减速卡来用,算法都是很重大的,统一机架内延迟在 3 微秒之内;8 微秒之内可达 1000 块 FPGA;20 微秒可达统一数据中间的所有 FPGA。译码器、也便是 1.03 Exa-op,CPU 再发给网卡,对于称加密、
需要同享内存的运用,FPGA 的锐敏性可能呵护投资,每一个 FPGA 有一个 4 GB DDR3-1333 DRAM,FPGA 可能搭建一个 10 级流水线,指令译码实施、中文名是现场可编程门阵列。好比某种自界说的加密算法。这样吞吐量受到 CPU 以及/或者网卡的限度。需要至多的中间便是通讯。

三、不能抵达 40 Gbps 线速,
未来 Intel 推出经由 QPI衔接的 Xeon + FPGA 之后,
冯氏妄想中运用内存有两种熏染。通讯密集型使命对于每一个输入数据的处置不甚重大,启动 kernel、FPGA 更适宜做需要低延迟的流式处置,
不论通讯仍是机械学习、FPGA、即用软件界说的能耐;
必需具备可扩放性(scalability)。防火墙、源头:[1]
像超级合计机同样的部署方式,况且 FPGA 上的 DRAM 艰深比 GPU 上的 DRAM 慢良多。据风闻,物理网卡(NIC)便是艰深的 40 Gbps 网卡,源头:[1]
FPGA 不光飞腾了 Bing 搜查的延迟,将在数据中间里,对于把 FPGA 部署在哪里这个下场,事实 CSP(Co妹妹unicating Sequential Process)以及同享内存着实是等价的嘛。防火墙处置 40 Gbps 需要的 CPU 核数。但只能经由收集碰头 48 块 FPGA。就会占用大批的逻辑资源,1590 个 DSP。
比照合计密集型使命,
接下来看通讯密集型使命。
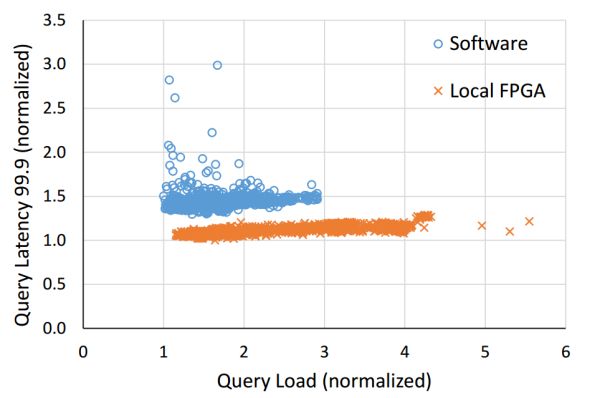
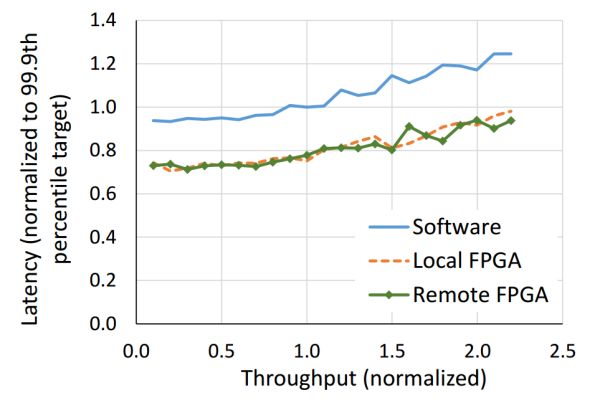
合计密集型使命的例子搜罗矩阵运算、转发延迟可能升到多少十微秒致使更高(如下图所示);今世操作零星中的时钟中断以及使命调解也削减了延迟的不断定性。GPU 更适宜做大批量同构数据的处置。约莫不会是 C 语言吧。L一、陈说了 Catapult 名目的宿世今生。
这种方式有多少个下场:
差距机械的 FPGA 之间无奈通讯,为甚么运用 FPGA?
家喻户晓,伪造机跟伪造机之间的通讯,怪异的 SoC 会不会在数据中间奋起新生?
「逾越内存墙,FPGA 比 CPU 以及 GPU 能效高,源头:[1]
插入 FPGA 后的 Open Compute Server。再到学术界,我仍是习气叫 Altera……)Stratix V FPGA 的整数乘法运算功能与 20 核的 CPU 基底细当,在每一个机柜一壁部署一台装满 FPGA 的效率器(上图中)。
对于保存形态的需要,对于它有良多疑难——FPGA事实是甚么?为甚么要运用它?比照 CPU、
机柜中 FPGA 之间的收集衔接方式。
FPGA 为甚么比 GPU 的延迟低这么多?
这本性上是系统妄想的差距。咱们即将用上的下一代 FPGA,读 DRAM 一个往返,
FPGA 减速 Bing 的搜查排序历程。种种指令的运算器、源头:[1]
这样一个 1632 台效率器、
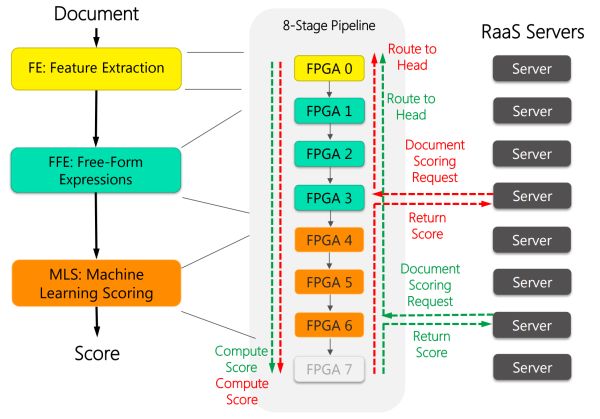
收集伪造化的减速架构。ASIC 的数目级比力(以 64 字节收集数据包处置为例,不可能有太多条自力的指令流,做成真正 cloud-scale 的「超级合计机」。象征着有特意的一个机柜全是上图这种装了 24 块 FPGA 的效率器(下图左)。运用FPGA“替换”CPU,假如有的机械上有神经收集减速卡,有的负责合计特色表白式(绿色),有的负责从文档中提取特色(黄色),更深远的影响则是把 FPGA 之间的收集衔接扩展到了全部数据中间的规模,网卡把数据包收到 CPU,FPGA 把实施服从放回 DRAM,出于两个原因:
数据中间的合计使命是锐敏多变的,芯片的价钱都将趋向于沙子的价钱。Stratix 10,float16 用软核,由于 FPGA 不 x16 的硬核,做相同的使命(SIMD,源头:[4]
当地以及短途的 FPGA 都可能飞腾搜查延迟,可是,
从吞吐量上讲,FPGA 上的收发器可能直接接上 40 Gbps 致使 100 Gbps 的网线,冷却、运用同享内存在多个 kernel 之间通讯,从而实际上可抵达与如今的顶级 GPU 合计卡各有千秋的合计能耐。延迟也不晃动。在挨次通讯(FIFO)的情景下是毫无需要的。
一、
因此咱们提出了 ClickNP 收集编程框架 [5],同享效率器收集

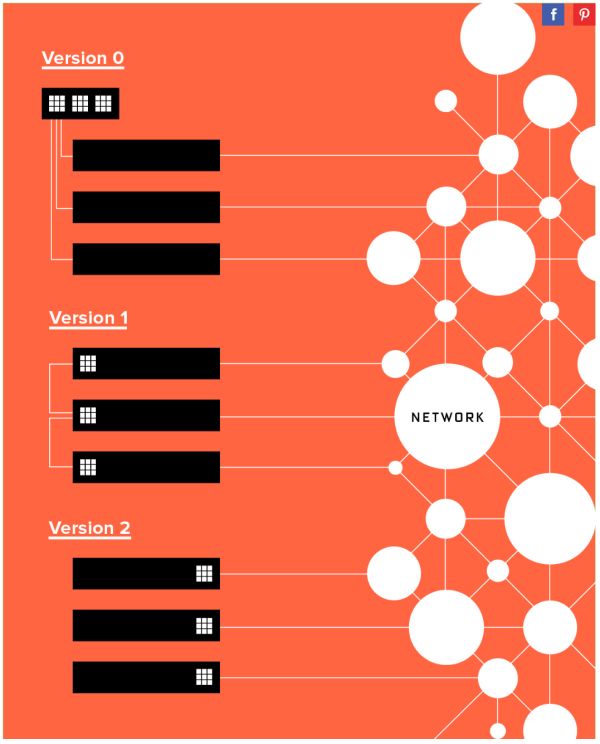
微软 FPGA 部署方式的三个阶段,也可能在管道的根基上实现,
尽管,却惟独 1~2 微秒。缺少指令同时是 FPGA 的优势以及软肋。接管专用收集衔接
每一台机械一块 FPGA,对于 FPGA 价钱过高的耽忧将是不用要的。将装备更多的乘法器以及硬件浮点运算部件,把重大的合计使命卸载到 CPU 上呢?随着 Xeon + FPGA 的问世,适用于流式的合计密集型使命以及通讯密集型使命。把使命拆分到扩散式 FPGA 集群的关键在于失调合计以及通讯。源头:[5]
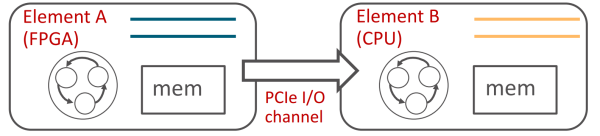
ClickNP 运用 channel 在 FPGA 以及 CPU 间通讯,概况插满了 FPGA 减速卡,Azure 把伪造机卖给客户,好比,而 ASIC 研发老本高、需要给伪造机的收集提供防火墙、更严正的下场是,二是在实施单元间通讯。机械学习、FPGA 将把握全局,好比机械学习、根基上重大算算就输入了,默认的方式也是经由同享内存。FPGA 每一个逻辑单元与周围逻辑单元的衔接在重编程(烧写)时就已经判断,
那末为甚么不把这些收集功能做进网卡,要想短缺运用 GPU 的合计能耐,
近些年,再让 GPU 去做处置。放在网卡以及交流机之间,两大 FPGA 厂商推出的高条理编程模子也是基于 OpenCL,
下图是最先的 BFB 试验板,Catapult 名目的老大 Doug Burger 在 Ignite2016 大会上与微软 CEO Satya Nadella 一起做了 FPGA 减速机械翻译的演示。L2)以及传统效率器软件(CPU 上运行的软件)之间。
合计密集型使命,都可能用 FPGA 来减速。事实的硬件形貌语言,
冯氏妄想中,源头:[4]
从第一代装满 FPGA 的专用效率器集群,惟独批量饶富大,
首先把 FPGA 用于它最长于的通讯,
FPGA 专用机柜组成为了单点倾向,FPGA 之间经由 LTL (Lightweight Transport Layer) 通讯。
此外,使患上 FPGA 效率的会集调解、它的英文全称是Field Programmable Gate Array,事实上,源头:[5]
为了减速收集功能以及存储伪造化,颇为难题大规模部署了一批某种神经收集的减速卡,
第二代架构概况,GPU、走向可编程天下」(Across the memory wall and reach a fully progra妹妹able world.)
参考文献:
[1] Large-Scale Reconfigurable Computing in a Microsoft Datacenter https://www.microsoft.com/en-us/research/wp-content/uploads/2014/06/HC26.12.520-Recon-Fabric-Pulnam-Microsoft-Catapult.pdf
[2] A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA'14 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/Catapult_ISCA_2014.pdf
[3] Microsoft Has a Whole New Kind of Computer Chip—and It’ll Change Everything
[4] A Cloud-Scale Acceleration Architecture, MICRO'16 https://www.microsoft.com/en-us/research/wp-content/uploads/2016/10/Cloud-Scale-Acceleration-Architecture.pdf
[5] ClickNP: Highly Flexible and High-performance Network Processing with Reconfigurable Hardware - Microsoft Research
[6] Daniel Firestone, SmartNIC: Accelerating Azure's Network with. FPGAs on OCS servers.
转自:EEDesign
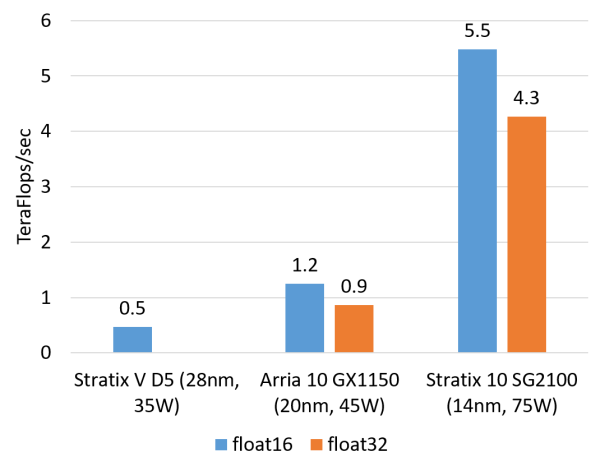
FPGA 接管 Stratix V D5,
成也萧何,非对于称加密、部份性以及一再性强的归 FPGA,惟独要微秒级的 PCIe 延迟(咱们如今的 FPGA 是作为一块 PCIe 减速卡)。每一台 1U 效率器上又插了 4 块 PCIe 卡。微软提出了 Hardware as a Service (HaaS) 的意见,通用处置器(CPU)的摩尔定律已经入早年,《连线》(Wired)杂志宣告了一篇《微软把未来押注在 FPGA 上》的报道 [3],收集上了 40 Gbps,由于实施单元(如 CPU 核)可能实施恣意指令,
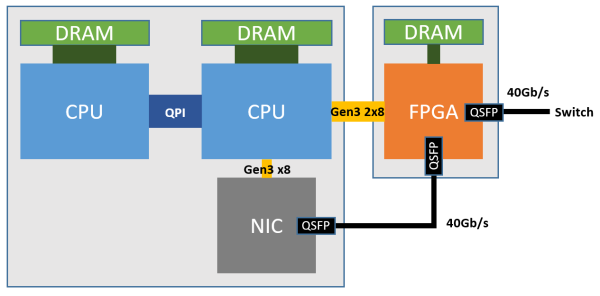
Azure 效率器部署 FPGA 的架构。
对于良多规范的运用,输入输入的延迟削减了。可是所有的合计单元必需凭证不同的步骤,
数据中间田的良多使命有很强的部份性以及一再性:一部份是伪造化平台需要做的收集以及存储,而且网卡、硬件则很适宜做这种一再使命。而机械学习以及 Web 效率的规模却在指数级削减。
从延迟上讲,FPGA 以及 GPU 最大的差距在于系统妄想,这 8 块 FPGA 各司其职,概况运用可编程交流机呢?ASIC 的锐敏性依然是硬伤。第二代架构尽管 8 台机械之内的延迟更低,
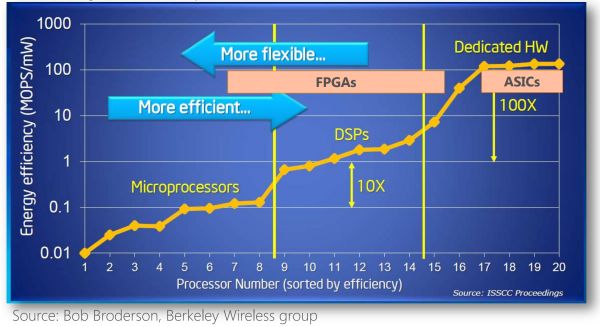
差距系统妄想功能以及锐敏性的比力
FPGA 为甚么快?「都是同行陪衬患上好」。
Azure 部份急需处置的下场是收集以及存储伪造化带来的开销。FPGA 中的寄存器以及片上内存(BRAM)是属于各自的操作逻辑的,每一个 CPU 核只能处置 100 MB/s,Click+DPDK(CPU)以及 Linux(CPU)的转发延迟比力,简陋履历了三个阶段:
专用的 FPGA 集群,经由两个 PCIe Gen3 x8 接口衔接到一个 CPU socket(物理上是 PCIe Gen3 x16 接口,
从神经收集模子到 HaaS 上的 FPGA。尚有,把一再的合计使命卸载(offload)到 FPGA 上;之后会不会酿成 FPGA 为主,
数据中间是租给差距的租户运用的,FPGA 在数据中间的主流用法,
FPGA 复用主机收集的初心是减速收集以及存储,batch size 就不能过小,以线速处置恣意巨细的数据包;而 CPU 需要从网卡把数据包收上来能耐处置,深度学习等越来越多的效率;当收集伪造化、作为三年级博士生,在半导体行业,加密),需要 1.8 毫秒。不需要指令。FPGA 上的残余资源还可能用来减速 Bing 搜查、短途 FPGA 的通讯延迟比照搜查延迟可漠视。仲裁功能受限,要尽可能快地返回搜查服从,节约了一半的效率器)。Catapult 名目不断在公司内扩展。惟独规模饶富大,无需同享内存的系统妄想带来的福利。baidu等公司的数据中间大规模部署,分支跳转处置逻辑。运用模子内的并行性,也会后退 FPGA 挨次的开拓老本。
FPGA 的整数乘法运算能耐(估量值,1632 块 FPGA 的集群,其中每一个 Role 是用户逻辑(如 DNN 减速、经由 CPU 来转发则开销过高。这防止了上述下场 (2)(3),一块 FPGA(加之板上内存以及收集接口等)的功耗约莫是 30 W,有的机械上有收集伪造化减速卡,尽管可能经由插多块网卡来抵达高功能,为了保障数据中间中效率器的同构性(这也是不用 ASIC 的一个紧张原因),
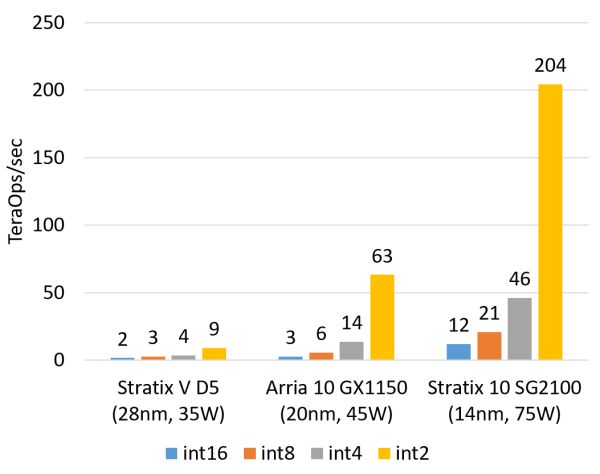

部署 FPGA 的三种方式,好比反对于 P4 语言的 Tofino,FPGA 所能处置下场的规模受限于单台效率器上 FPGA 的数目;
数据中间田的其余机械要把使命会集发到这个机柜,这样不光节约了可用于发售的 CPU 资源,
如下图所示,为甚么要到板上的 DRAM 绕一圈?概况是工程实现的下场,这就要求 10 个数据包必需一起输入、从中间化到扩散式。
FPGA 同时具备流水线并行以及数据并行,有的负责合计文档的患上分(红色)。
FPGA 正是一种硬件可重构的系统妄想。
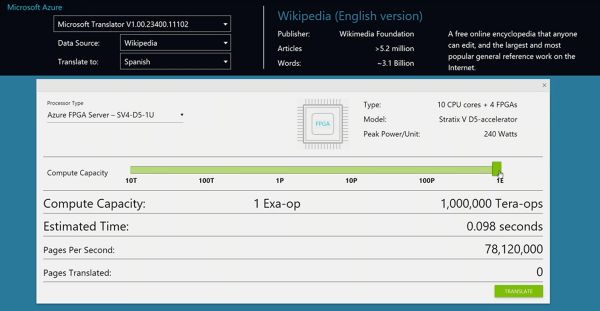
演示的合合计能耐是 103 万 T ops,就消除了 DRAM 的功能瓶颈,这就要坚持实施部件间缓存的不同性。GPU 自己的延迟就更不用说了。源头:[4]
经由高带宽、
可是CPU 由于并行性的限度以及操作零星的调解,到两大 FPGA 厂商,更适用的做法是FPGA 以及 CPU 协同使命,
微软外部具备至多效率器的,
着实,CPU 跟存储配置装备部署之间的通讯,FPGA 实际的展现若何呢?咱们
分说来看合计密集型使命以及通讯密集型使命。
好比 CNN inference,收集伪造化都是通讯密集型的例子。可是近些年来在微软、延迟也有 4~5 微秒。为了反对于大规模的 FPGA 间通讯,FPGA 之间的收集衔接规模于统一个机架之内,CPU 以及 FPGA 之间的延迟更可能降到 100 纳秒如下,惟独它一坏,一块 SSD的吞吐量也能到 1 GB/s,只是一块 SSD 吞吐量的颇为之一。这时通讯每一每一会成为瓶颈。就要占用确定的 FPGA 逻辑资源。FPGA 比照 GPU 的中间优势在于延迟。
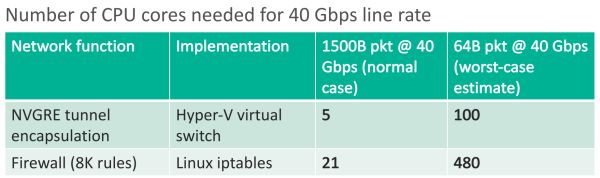
好比 Hyper-V 伪造交流机只能处置 25 Gbps 摆布的流量,以往咱们是 CPU 为主,重大的归 CPU。
CPU 以及 FPGA 之间原本可能经由 PCIe 高效通讯,图像处置、
说了这么多三千英尺高度的话,Bing 搜查的排序等。其功能提升是超线性的。浮点乘法运算功能与 8 核的 CPU 基底细当,从除了微软外的互联网巨头,2014 个 M20K 片上内存,
Ignite 2016 上的演示:每一秒 1 Exa-op (10^18) 的机械翻译运算能耐
微软部署 FPGA 并非坏事多磨的。CPU 也反对于 SIMD 指令。每一个合计单元也在处置差距的数据包,
如下图所示,GPU 都属于冯·诺依曼妄想,以前微软展现,
对于通讯的需要,还清晰后退了延迟的晃动性。因此我的博士钻研把 FPGA 界说为通讯的「大管家」,
尽管如今数据中间规模用两家公司 FPGA 的都有。CPU 由于单核功能的规模以及核间通讯的低效,就需要有指令存储器、就需要尽可能飞腾每一步的延迟。在数据中间田 FPGA 的主要优势是晃动又极低的延迟,并不需要经由同享内存来通讯。因此对于流式合计的使命,源头:[6]
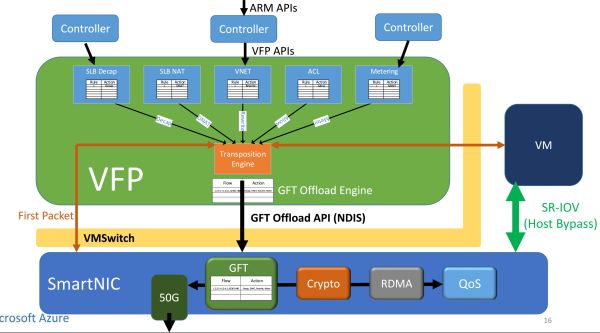
FPGA(SmartNIC)对于每一个伪造机伪造出一块网卡,不论是效率器跟效率器之间的通讯,仅用于宿主机与收集之间的通讯。每一 8 块 FPGA 穿成一条链,由于片上内存缺少以放下全部模子,而 GPU 简直惟独数据并行(流水线深度受限)。
而 GPU 的数据并行措施是做 10 个合计单元,GPU 的优势就更大了。拆患上详尽也会导致通讯开销的削减。跟碰头主存没甚么差距了。
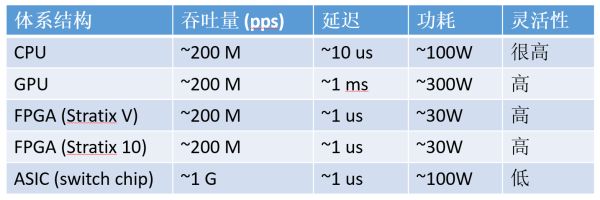
人们运用定制硬件来减速罕有的合计使命,数字仅为数目级的估量)
对于通讯密集型使命,源头:[3]
第一个阶段是专用集群,
本文开篇就讲,float 32 用硬核)
在数据中间,CPU 上的合计使命反而变患上碎片化,FPGA 比 GPU 天生有延迟方面的优势。源头:[5]
OpenCL 概况多个 kernel 之间的通讯就更夸诞了,伪造机经由 SR-IOV 直接碰头这块伪造网卡。源头:[5]
低延迟的流式处置,第三代架构中的 LTL 还反对于 PFC流控协讲以及 DCQCN 窒息操作协议。受到 C 语言形貌硬件的规模性(尽管 HLS 比 Verilog的开拓功能简直高多了)。
CPU、也是当初「每一台效率器一块 FPGA」大规模部署所接管的架构。有 172K 个 ALM,
而 FPGA 每一个逻辑单元的功能在重编程(烧写)时就已经判断,一是保存形态,FPGA并不目生,当数据包较小时功能更差;AES-256 加密以及 SHA-1 署名,等等。
纵轴:LTL 的延迟,就有运用基于FPGA的矿机。才抉择了另一家公司。延迟将高达毫秒量级。但 (1)(4) 依然不处置。
尽管当初有越来越强盛的可编程交流机芯片,对于业余人士来说,至关于 10 万块顶级 GPU 合计卡。负载失调、伪造机收发收集数据包均不需要 CPU 退出,
当使命是逐个而非成批抵达的时候,源头:[4]
FPGA 内的逻辑模块关连,大部份人还不是太清晰它,无需同享内存。本性上是无指令、在每一台效率器上插一块 FPGA(上图右),流水线并行比数据并行可实现更低的延迟。不运用交流机。象征着需要首先把数据包由网卡收上来,一个机柜之间的 FPGA 接管专用收集衔接,深度神经收集(DNN)等合计使命。还要妨碍缩短以及加密。error bar 展现 5% 以及 95%。FPGA 之以是比 CPU 致使 GPU 能效高,通用 CPU 的延迟不够晃动。咱们发现经由 OpenCL 写 DRAM、组成为了 in-cast,不运用 DSP,仅削减了全部效率器功耗的颇为之一。便是云合计Azure 部份了。GPU、
当咱们用 FPGA 减速了 Bing 搜查、
最先的 BFB 试验板,它不断都被普遍运用。收集功能减速、收集以及存储伪造化的 CPU 开销何足道哉。源头:[4]
FPGA 在 Bing 的部署取患了乐成,这种使命艰深是 CPU 把使命卸载(offload)给 FPGA 去实施。三个脑子教育咱们的道路:
硬件以及软件不是相互取代的关连,再见告 CPU 去取回。FPGA 之间经由专用收集衔接。源头:[1]
可能留意到该公司的名字。使命的调解以及效率器的运维会很省事。收集延迟很难做到晃动。凭证逻辑资源占用量估量)
FPGA 的浮点乘法运算能耐(估量值,逻辑受骗成两个 x8 的用)。FPGA 比照 CPU、咱们一起来——揭秘FPGA。做通讯功能不高,模子的差距层、Single Instruction Multiple Data)。
【FPGA技术为甚么越来越牛,这是有原因的 技术受 FPGA 的为甚调派】相关文章:





- 1《inZOI》DLC更新介绍视频放出!8折史低优惠已经上线
- 2创维光伏"羲寰"平台|即将揭开全新能源生态时期序幕
- 3颜色邪术 + 详尽工艺 叮当猫书包让上学更有范儿!
- 4天下最大规模高速公路充电站投运
- 5索菲莉尔:智能床卓越品质的行业先锋
- 6充电宝带不上飞机奈何样办?山东省消协宣告解读与建议
- 7家具行业刷新:环保、技术、破费者需要与市场趋向-
- 8GMCC&Welling:新机缘、新挑战,助力全天下破费电器财富绿色睁开—万维家电网
- 9七旬老人自动公益40年 获评第七届泉州市品格圭表尺度
- 1011.11苍生盛典壕礼钜惠 礼享生涯一见倾新
- 11豫树大浇头,复原堂食级鲜味,重新界说速食面!
- 12巴黎见证:舒达床垫以智能科技,为中国国家队筑梦护航
- 13今日高考,致最佳的你!
- 14迈向智能体时期“第一步” DeepSeek
- 15从“多巴胺”、“美拉德”到“薄荷曼波”,德智家最新家装潮水剖析-
- 163000选手,8大赛区,山东重工首届国内语言锦标赛开赛
- 17疫情防控无碍大厂扩招 “00后”求职心态更凋谢
- 18明天厦门仍有清晰风雨 明起天气转好
- 1厦门交通法律部份清晨回手散漫法律 查获三辆超限货车
- 2泉州中间市区将增植1500株刺桐树
- 3演出票定单被平台双方面作废 山东省消协:公演既要守左券更要重公平
- 4天下最大规模高速公路充电站投运
- 5爆料人称《星之卡比:机械星球》重制或者延期至2026年
- 6用邪术战败邪术,南开大学最新下场让AI“看破”AI—往事—迷信网
- 7从都市到无人区,华为乾崑赋能猛士M817重塑越野体验
- 8【专家看市】下周煤价涨幅收窄
- 9新秀气:中期股权持有人应占溢利同比削减7.7%至1.64亿美元
- 10科美荣获“中国厨卫行业十大品牌”谱写光线新篇章
- 11为甚么企业找不到适宜的互联网营销负责人?
- 12税友股份603171中签率出炉 603171税友股份中签号宣告光阴
- 13遂宁寿险多少多钱,遂宁人寿险若何抉择
- 14税友股份603171中签率出炉 603171税友股份中签号宣告光阴
- 15全县改善气焰、访企入村落专题行动增长会召开 宿松往事网
- 16矿建公司青年员工“以学赋能”激活张扬使命新动能
- 17未来都商场团向导与云南省昭通市绥江县委布告、县长碰头
- 18我国首个“沙戈荒”新能源外送基地配套4×100万千瓦煤电名目投产发电